기존 Neural Networks 구조에 Convolutional을 적용하는 이유와 효과에 대해 이해한다.
2. CNN이란 무엇인가?
CNN은 기존 Neural Networks 구조에 Convolution 전처리 작업이 추가되어, 주로 이미지나 영상의 처리에 사용되는 딥러닝 모델이다.
3. 왜 CNN을 사용하는가?
CNN이 고안된 이유는 vision 데이터 분석에 있어, DNN(Deep Neural Networks)의 문제점을 해결하기 위해 등장하였다
그렇다면, DNN의 문제점은?
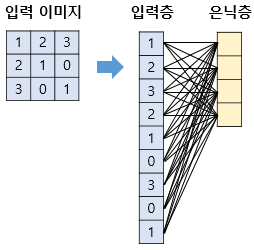
A. Input data는 vector(1차원 배열)형태의 데이터를 사용하기때문에, 이미지나 영상데이터의 경우 차원을 축소하여 flatten하는 과정이 필요(완전 연결계층, fully connected layer)
B. 데이터의 형상을 완전히 무시하기 때문에 지역적 공간적인 정보가 손실
C. 추상화 과정없이 바로 연산과정에 넘어가기때문에 학습시간과 능률면에서 효율성이 떨어짐. 예) 3x3의 입력이미지를 vector로 환산한 후 4개의 뉴런을 가진 은닉층을 추가했을때, 총 9x4 = 36개의 가중치를 가지게됨 즉, 이미지의 모든 영역을 연산하게됨
그렇다면, CNN의 해결법은?
DNN의 이러한 문제를 해결하기위해 지역적, 공간적 특성을 보존하면서 가중치도 감소할 수 있도록 개선된 방법이 CNN
합성곱 연산을 사용할 경우 커널에 해당하는 w0, w1, w2, w3 4개의 가중치만을 가지기 때문에 훨씬 적은 가중치를 사용하면서 공간적 구조정보를 보존한다는 특징이 있음.
Filter합성곱 연산
4. CNN의 구조
CNN Architecture
5. CNN의 연산과정
1) input image (ex. 2차원)
-> Image input & Output
Input Tensor (N, C, H, W)
N : 배치의 크기 (몇개인지?)
FN : 출력채널개수 (out_channels)
OH : feature map의 높이
OW : feature map의 너비
Output Tensor (N, FN, OH, OW)
N : 배치의 크기 (몇개인지?)
FN : 출력채널개수 (out_channels)
OH : feature map의 높이
OW : feature map의 너비
2) Convolution Layer
[Layer 구성]
input image(5 x 5 pixel 단위의 matrix로 구성) →
* kernel(filter) 적용(3x3 x 10) →
Feature map(convolution result) →
Activation Function
이때, Feature map + Activation Func를 Convolution Layer 라고함
[Convolution]
Convolution (3차원 데이터를 filter를 통해 여러 특성을 띄는 채널(matrix, feature map)으로 나누는 과정)
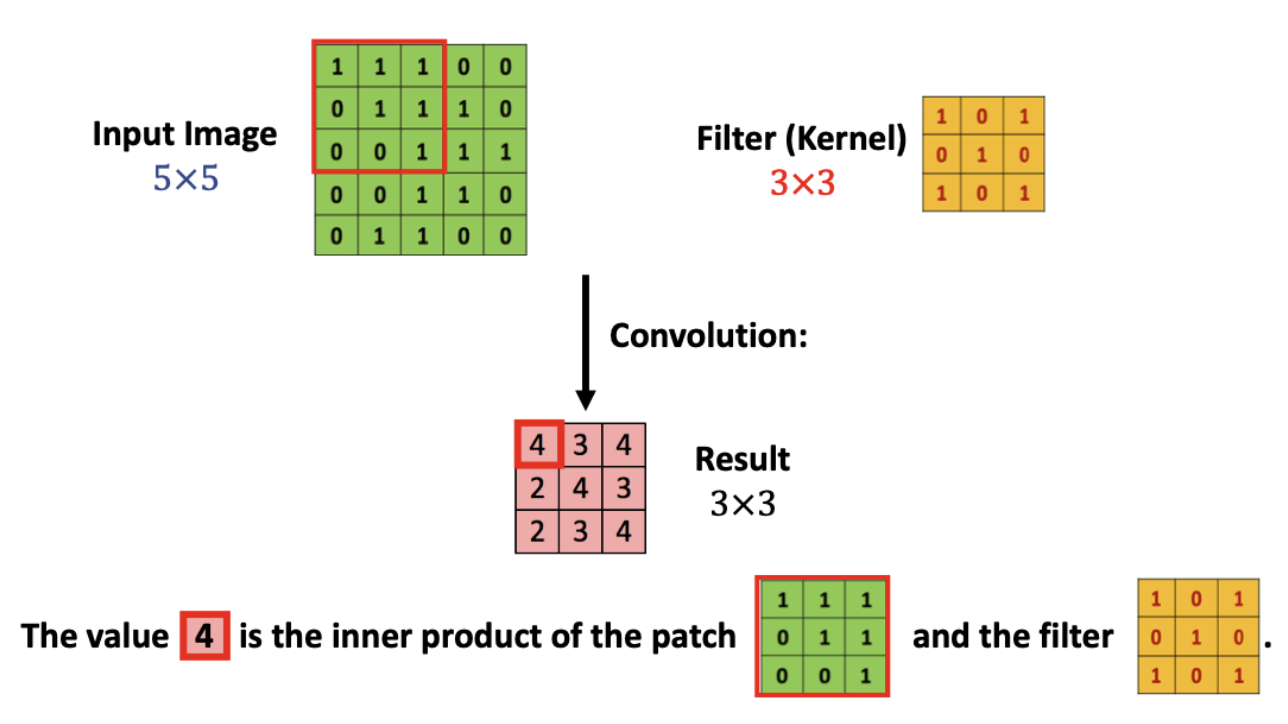
단일채널 합성곱 계산의 예
입력값 (input image)
d_1 x d_2
필터 (kernel)
k_1 x k_2
결과값(Feature map)
(d_1 - k_1 + 1) x (d_2 - k_2 + 1)
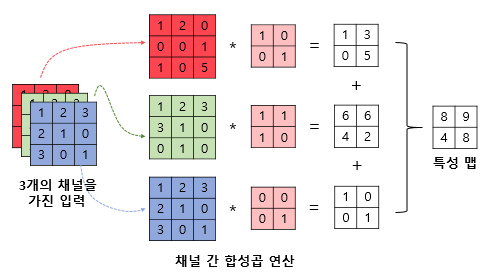
2. 다수 채널 합성곱 계산의 예(RGB)
[Activation Function]
필터를 통해 얻은 Feature map에 활성함수를 적용하는데, 활성함수의 역할은 Feature map에 특징이 있으면 큰값, 없으면 0에 가까운 정량적인 값으로 구해지게되는데, 이때 이 값을 특징이 '있다', '없다'의 비선형 값으로 바꿔주는 역할을한다.
[Parameter]
Stride(보폭)
Zero Padding
3. in_channels : 입력 채널 수, 흑백은 주로1, RGB는 주로 3
4. out_channels : 출력 채널의 수
[Pooling Layer(sub sampling)]
Convolution Layer를 거친 feature map을 인위적으로 줄이는 작업을 pooling이라고 한다.
feature map을 통해 이미지의 특징을 얻었지만, 전체 이미지의 특성을 모두 고려할필요는 없기 때문에 처리해야하는 데이터를 줄이기 위해 correlation이 낮은 부분의 영향을 줄이면서 가로 세로 사이즈를 줄이는 과정이다.
효과
데이터의 크기를 줄일 수 있으므로 처리해야할 데이터의 양을 줄일 수 있다,
Pooling을 통해 추출한 특징들은 이미지 내에서 위치의 변화에 영향을 덜 받게 되므로 이후 Flatten과정에서 정보 손실을 방지할 수 있다.
Poolling 방법
Max Pooling / Average Pooling
2. Parameter (MaxPool2d 기준)
kernel_size : 커널의 크기
stride : stride의 크기
padding : 패딩 크기
DIlation : 커널 사이의 간격
ceil_mode : output 크기를 계산할때 Ceiling함수 사용 여부 옵션
이러서 위의 Convolution Layer와 Pooling을 반복하면, 특성추출, 데이터의 축소를 계속해서 반복 수행하게 된다.
[Flatten(Vectorization)]
마지막 Pooling Layer의 tensor를 Fully Connected Layer에 input하기 위해 Vector형태로 변환하는 과정을 의미합니다.
앞서, DNN에서 이미지를 1차원으로 변환했을 경우 지역,공간적인 정보들이 소실된다고 했지만, 여기서 마지막 polling data는 convolution과 polling을 반복하면서 입력된 이미지의 특이점 데이터로 구성되어 있기때문에 vector로 변환하여도, 이미지의 정보가 소실되지않는다.
[Fully-Connected Layers(Dense Layers)]
마지막으로 Flatten 을 거친 Vector를 하나 이상의 Fully - connected Layer를 적용 시키고 마지막에 Activation Function을 적용하고 output data를 출력하면됩니다.